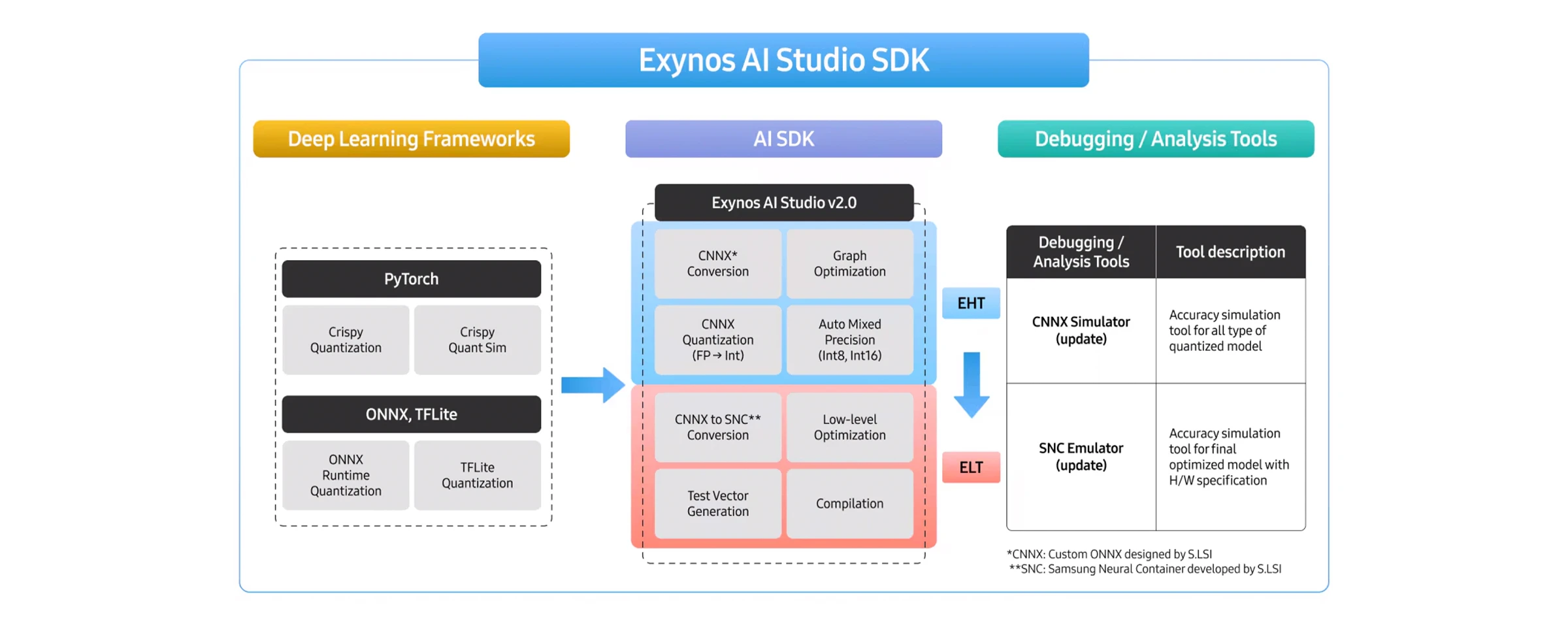
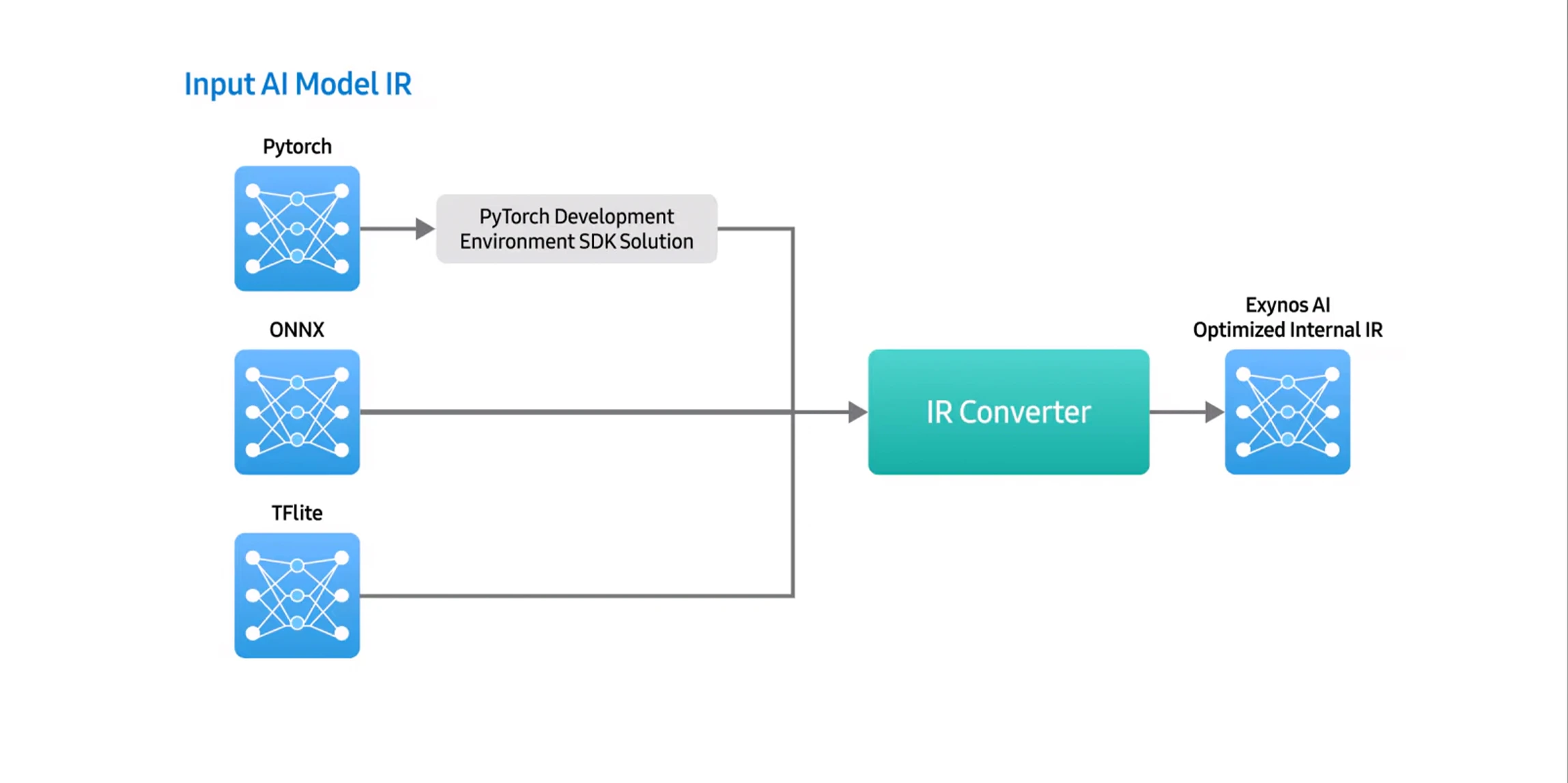
Exynos AI Studio is largely composed of the Exynos AI Studio High Level Toolchain (EHT) and the Exynos AI Studio Low Level Toolchain (ELT). Respectively, these perform advanced graph optimization and quantization at the model level, as well as SoC-specialized algorithms and compilation.EHT takes open-source framework IRs such as ONNX and TFlite as inputs, converts them into an internal IR through the IR Converter, and then modifies the model structure via Graph Optimization to make it suitable for execution on the NPU. Through quantization, it reduces the model size to a level that can run efficiently on-device.ELT carries out lowering operations optimized for each NPU generation, converting the model into a form that’s executable on hardware. Finally, the model passes through the Compiler, generating an on-device AI model that can run on the NPU.
Designing SDK Features To Handle Various AI Model IRsTo enhance the scalability of the SDK, it is essential to support multiple AI model IR formats. Samsung’s SDK currently supports open-source framework IRs such as ONNX and TFLite, and it is developing a strategy to strengthen PyTorch support. In particular, for generative AI models, performing graph optimization and quantization within the PyTorch development environment can minimize unnecessary conversions during model lowering, which enables the delivery of a more stable and efficient SDK.
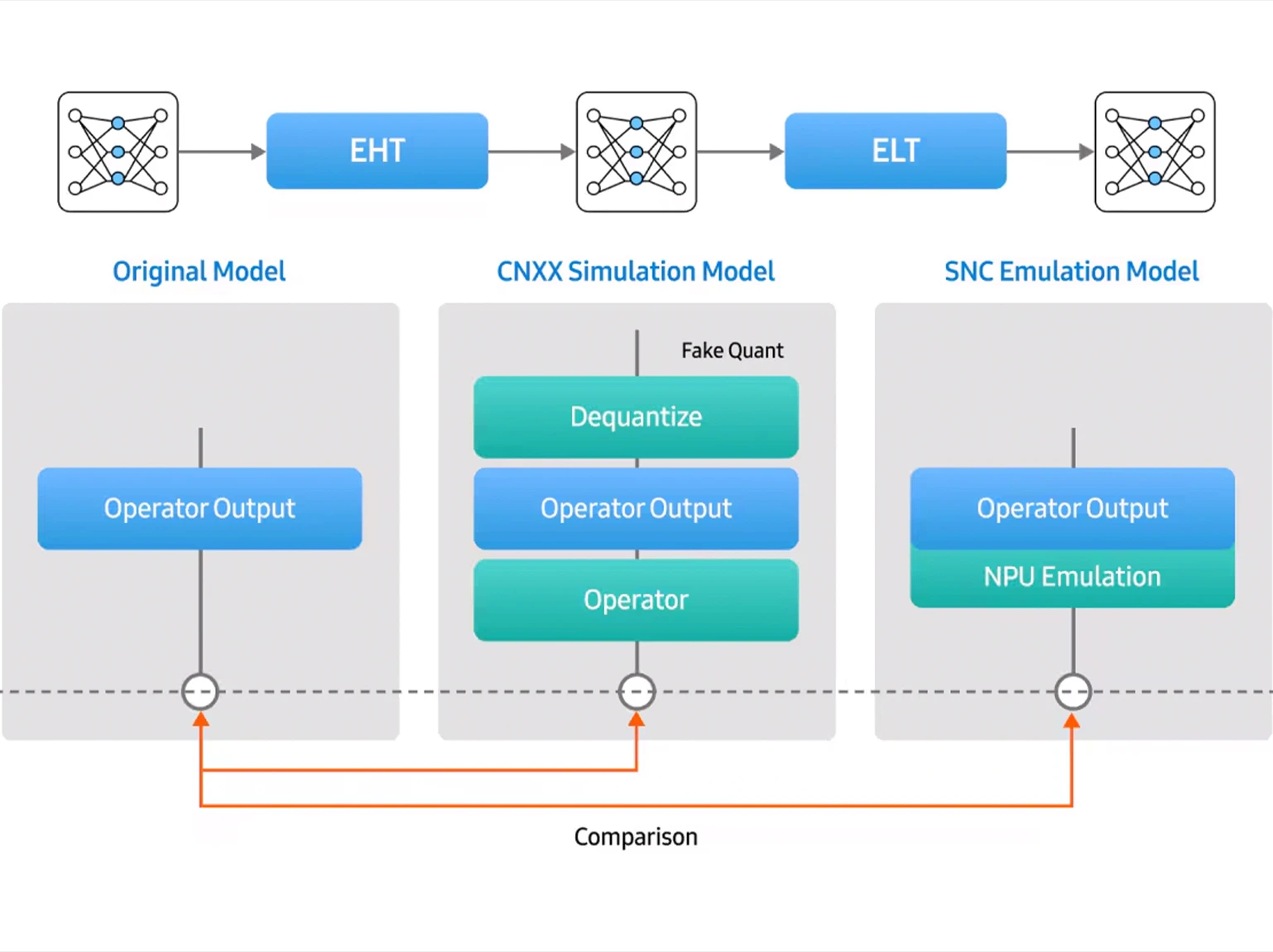
The output of the EHT module in Exynos AI Studio can be compared with the original model on an operator basis by using the Signal-to-Noise Ratio (SNR) metric through the simulation function. In the simulator, to process quantization information, specific operators are handled with de-quantize and quantize operations before and after inference, enabling computation through fake quantization. The results of the ELT module are validated for accuracy using the emulation function, in a manner similar to EHT verification. Since the emulator performs computations through emulation code that replicates the NPU hardware, it enables more precise validation.
Strategies for Advanced Graph Optimization and Quantization AlgorithmsAs AI models become more complex and larger in size, advancing the graph optimization and quantization algorithms supported by the SDK becomes even more essential.